clarifeye
Created: January 2, 2024
Background
Clarifeye is my undergraduate engineering capstone project that I am building with 3 of my friends. Below is a summary of our progress so far!
Problem Space & Needs Statement
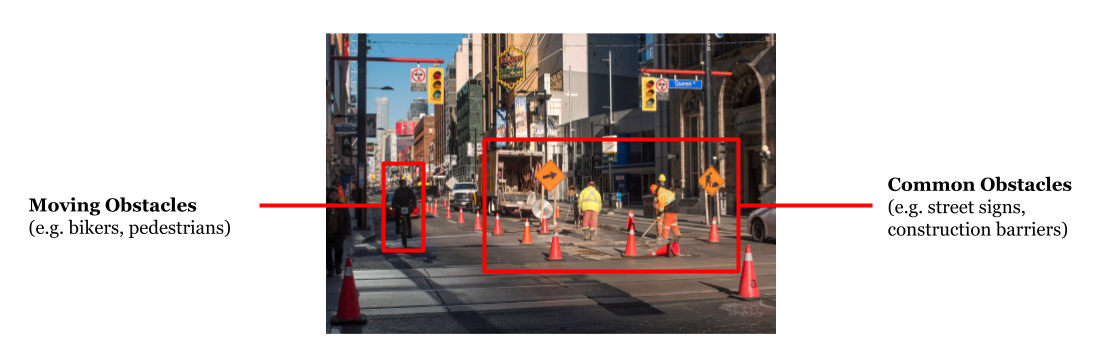
Navigating the complex urban landscapes poses a significant challenge for the close to 300M people worldwide with severe visual impairment (VI). Although traditional aids like white canes and guide dogs are able to help individuals with VI navigate around obstacles, they lack the capability to communicate to users about the identity of these obstacles. This gap in information not only hampers safe and efficient navigation but also restricts the user's ability to independently interact with their surroundings.
Our project aims to design a real-time device to address the challenge of outdoor obstacle identification for individuals with severe visual impairment that can be used alongside traditional aids (e.g. guide dogs and canes) to enhance the user’s ability to make informed decisions about their routes and increases their confidence and independence in outdoor navigation.
Goals
- Goal 1: Improve decision making:
- Metric: Accuracy & precision of object identification
- Metric: Speed of decision making - measure the time it takes for a user to make an informed decision after receiving the identification alert
- Metric: Quality of decision making - assess how often users make the correct or safer decision when informed about the type of obstacle in a given obstacle course
- Goal 2: User Confidence
- Metric: Conduct user surveys to gauge the level of confidence they feel while using the system
Early Concepts
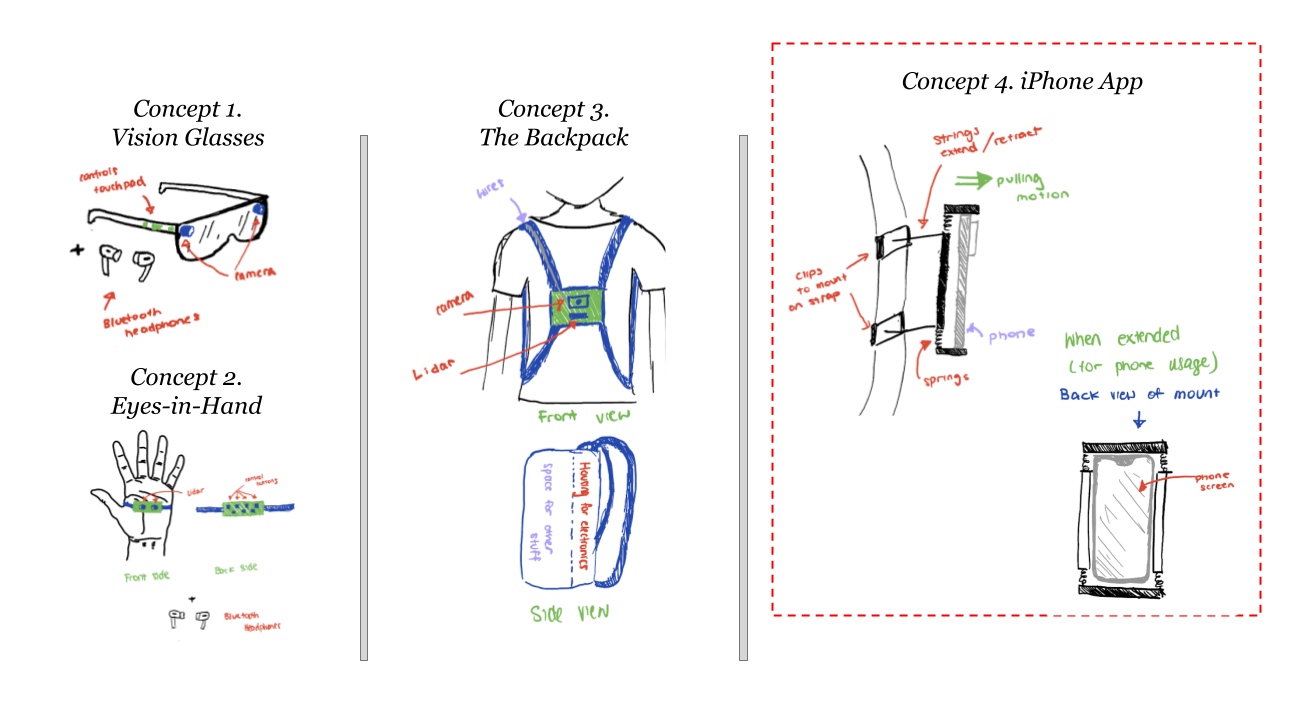
Initial concept generation included various ideas like smart glasses, a backpack with integrated sensors, and a 'eyes-in-hand' device. However, these were eventually streamlined to the development of an iPhone app.
An iOS app was selected, as opposed to Android, because Apple is well-known for its wide range of accessibility features and its wide spread adoption in the VI community (with over 75% of the VI community owning an Apple device according to surveys).
Requirements Gathering
Competitor Analysis
There's a variety of different type of solutions within the VI object detection/identification space like the WeWalk cane, and various cane attachments. However, to stay relevant for this analysis, we decided to focus on software-based VI solutions.
Navigation & GPS
Soundscape: Local landmarks and orientation
Lazarillo: Local Landmarks Categorized
Explore: Navigation and Local Landmarks
The first category of competitors and navigation & gps focused apps. They give users info on local landmarks and gives insights on orientation. They don’t provide any object or obstacle detection capabilities, they are purely GPS based. We can exclude them from analysis.
Object Detection
The second category are apps that do perform object detection. For Ayes and SeeingAI they are limited in the category of items that they do detect. For example Ayes only focuses on Traffic Lights.
Apple Magnifier can detect people, doors, and describe scenery which can be applicable to the outdoor obstacle detection use case. However, they have significant issues in user experience. For example there are several operations/clicks you would have to perform before you can get to the obstacle detection screen, creating friction. Also you have to turn on each mode (person, door, scenery) individually to use them. We can improve on this.

SeeingAI: Scene, Text, and Currency etc. Detection

OKOAyes: Traffic light detection only

Apple Magnifier: People, Doors, Scenes
Agent Support
BeMyEyes is definitely the most popular of all the applications. They allow visually impaired individuals to be paired up with an agent/volunteer for live support — it’s also expensive. A big caveat of this approach is time sensitivity. Agents are great for small tasks like help me check this label, however, in the use case that we are tackling, traveling outdoors, this can be time consuming/may not be a good use of agents times. Also there may be delays and lags in audio video preventing agents from providing time-sensitive and proper feedback on an obstacle (e.g. if the obstacle is moving).

BeMyEyes: Agent Live Support
User Interviews
Throughout the development process we conducted 15 and counting interviews with users of various backgrounds. Each of their perspectives helped us solidify our understanding of the problem and our potential approaches to the solution.
| ID | Type | User Demographic | Phase |
|---|---|---|---|
| 1 | Concept Generation | Medical Students | Concept Generation |
| 2 | Concept Generation | Professor of Optometry | Concept Generation |
| 3 | Concept Generation | Individual with VI | Concept Generation |
| 4 | Exploration | Individual with VI | Concept Screening |
| 5 | Exploration | Individual with VI | Concept Screening |
| 6 | Exploration | Individual with VI | Concept Screening |
| 7 | Exploration | Individual with VI | Concept Screening |
| 8 | Exploration | Individual with VI | Concept Screening |
| 9 | Exploration | Orientation and Mobility Specialist & Service Coordinator | Concept Screening |
| 10 | Exploration | Low Vision Specialist | Concept Screening |
| 11 | Exploration | Navigation and Mobility Specialist | Concept Screening |
| 12 | Idea Validation | Occupational Therapist | Concept Screening |
| 13 | Idea Validation | Disability Consultant | Concept Screening |
| 14 | User Study | High Technology Assessment Specialist with VI | Modeling / Prototyping |
| 15 | User Study | Individual with VI | Modeling / Prototyping |
Use Case Analysis

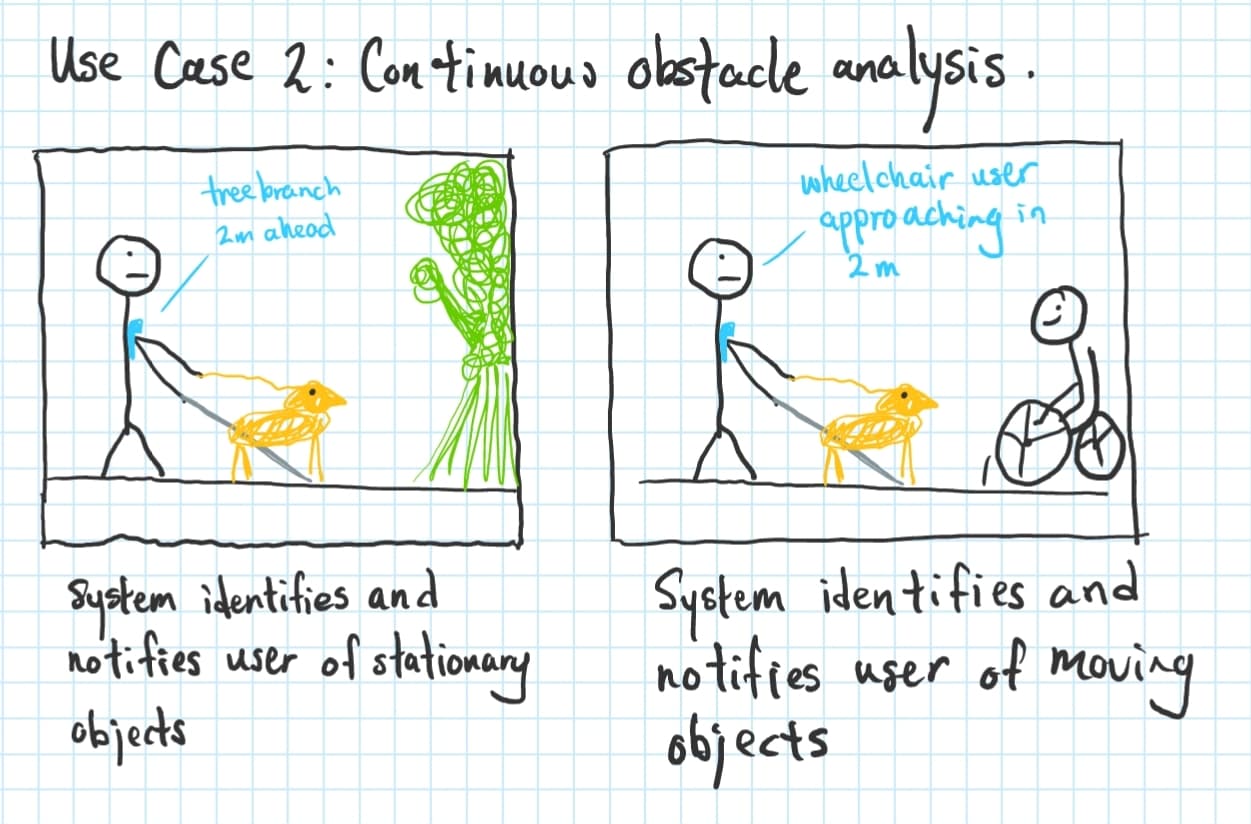
Case 1: Continuous Usage
Case 2: Ad Hoc Usage
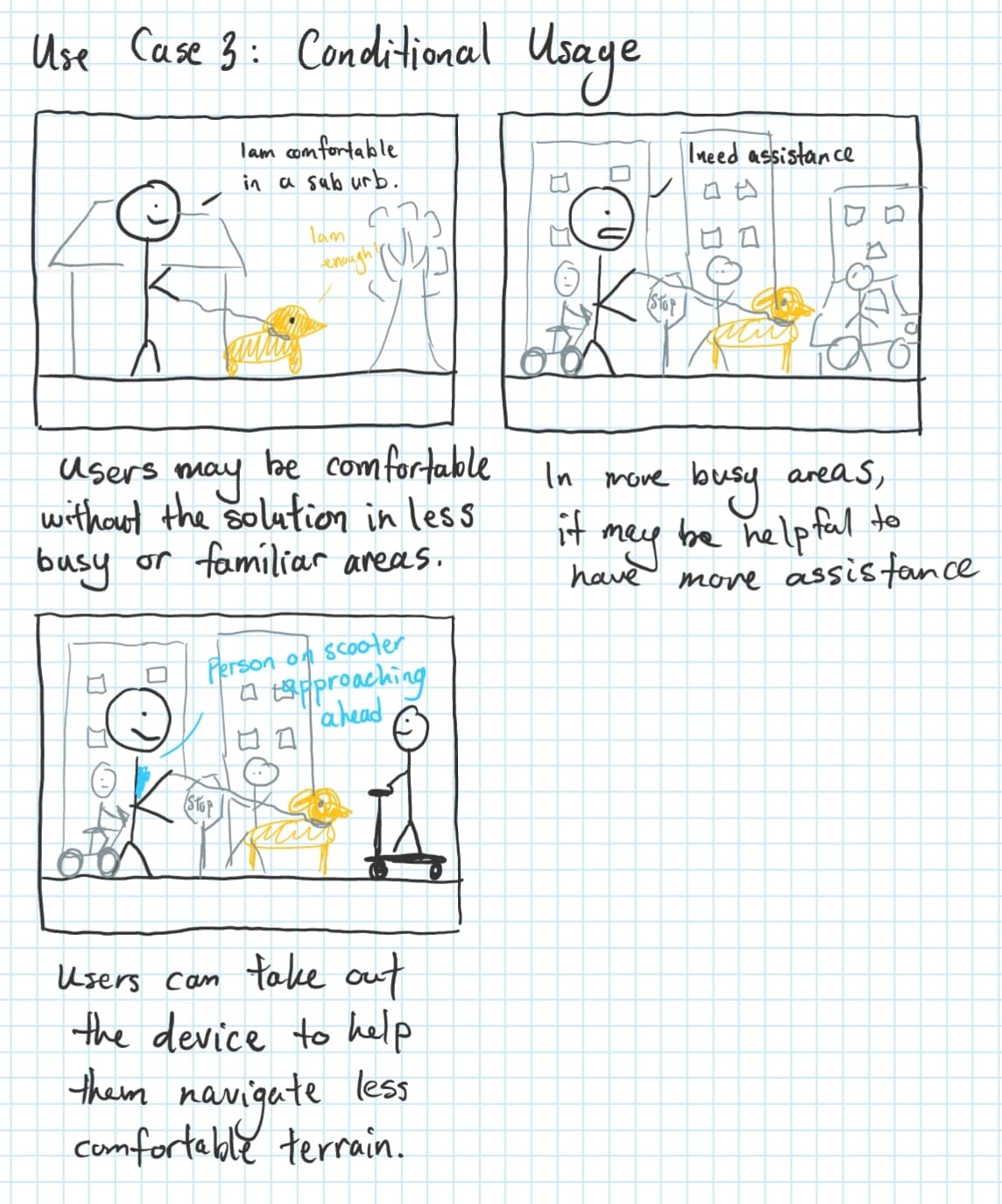
Case 3: Conditional Usage
Case 1: Continuous Usage
For users who want to be more aware, or need more assistance in navigation and mobility, they may choose to have their app on for continuous usage as they traverse the outdoors.
As things come and go, the system will notify the user of potential obstacles along the way.
Case 2: Ad Hoc Usage
For users with a strong sense of confidence in their ability to navigate and move through the city, having our solution on the whole time does not make sense for them. It could waste their battery and give unnecessary feedback. In these cases, it would be good for them to use this as an obstacle identification tool to help them gain more context around their surroundings and in turn avoiding potential accidents.
Without the obstacle identification, the user could have simply walked around the detected pylon obstacle and continued forward. Which would be no good!
Case 3: Conditional Usage
For users that need occasional assistance for specific circumstances, the solution can be used for short periods of time. For example, if user’s feel comfortable walking in sub-urbs, they may not need to use the solution, however, when the user gets to a more urban area like a city, then they may opt to use the solution to help them with their navigation & mobility.
Requirements Summary
Based on the information collected from above, we developed a concise list of key requirements:
| Description | Specification | Area |
|---|---|---|
| Detect obstacles in the path of the user | Detectable distance > 1.2 m | Vision: Software |
| Recognize common outdoor obstacles | Number of obstacles types recognized > 30 | Vision: Software |
| Correctly identifies common outdoor obstacles | Identification mAP @ 50 > 65% | Vision: Software |
| Have adequate visibility of the user’s environment | Field of view > 120 degrees | Vision: Hardware |
| Gauge proximity of the obstacle from user | Absolute relative error < 0.05 | Vision: Hardware |
| Operate in real-time to provide immediate feedback | Delay < 100 ms | Computation |
| Should minimally consume cellular data | Data consumption < 500 MB / hr | Computation |
| Easy to learn to use | User Training < 20 mins | UI/UX |
| Key functionality is activated quickly and easily | Activation time < 3s | UI/UX |
| Interface should be accessible for low-vision users | Web Accessibility Score (WAS) > 80% | UI/UX |
| Alert the user through via quick and intuitive feedback | User decision response time < 500 ms | UX: Feedback |
| Feedback provided prioritizes user safety | Feedback accuracy > 90% | UX: Feedback |
| Minimally interferes with cognition | Modalities < 3 | UX: Feedback |
| Have a minimum battery life to sustain a day's use | Duration per charge > 3 hrs | Hardware |
| Has portable weight | Weight < 5 lbs | Hardware |
| Has high durability | Pass drop test > 2 m | Hardware |
| Should be affordable for the end-user | Cost < $30 | Hardware |
Obstacle Prioritization
Leveraging publicly available obj id datasets like COCO, NuScenes, and VIDVIP (Visual Dataset for Visually Impaired Persons), we chose to prioritize training the model on the following outdoor-based obstacles.
| Priority | Obstacles |
|---|---|
| 1 | Vehicles (car, bus, truck, bicycle), People (general), Stairs, Walls, Barriers (general), Poles, Trees, Construction, Potholes |
| 2 | Bench, Road signs (distinctions), Road markings (distinctions), Traffic cones, Fire hydrants, Traffic lights (distinctions), Ice, Doors |
| 3 | People (distinctions), Puddles, Barriers (distinctions), Shrubs, Trash cans, Other vehicles (scooters), Animals (distinctions) |
Prototyping
Engineering
Software Development
In the software development stage of ClarifEye, we had a choice between two frameworks, AVFoundation and ARKit. AVFoundation was initially appealing for its fine control over camera settings and synchronized LiDAR data. However, ARKit, with its simpler interface for AR interactions, proved more aligned with our user experience goals despite its limited camera configurability. We committed to ARKit, favoring its streamlined functionality for augmenting real-time feedback into the camera scene over the granular control offered by AVFoundation. Swift UI was also utilized in the UI development for its dynamic and responsive interface capabilities.
Camera & Depth
With camera and depth, we faced a choice between the default depth estimation model and the iPhone LiDAR sensor. The depth estimation model promised higher resolution but was incompatible with ARKit and computationally heavier. LiDAR's lower resolution and sparsity were acceptable trade-offs for its lighter computational load and integration with ARKit.
Data Modeling
The data modeling for our project involved fine-tuning a YOLOv8 model using three specific datasets: VIDVIP, Obstacle-Dataset, and Staircase dataset. This allowed us to ensure a balanced representation of various obstacle types during training. We focused on model accuracy and compactness to enable real-time identification with minimal latency on the iPhone. The YOLOv8 model proved more efficient than YOLOv3, requiring fewer computational resources while delivering higher precision.
Design
Design Prototype
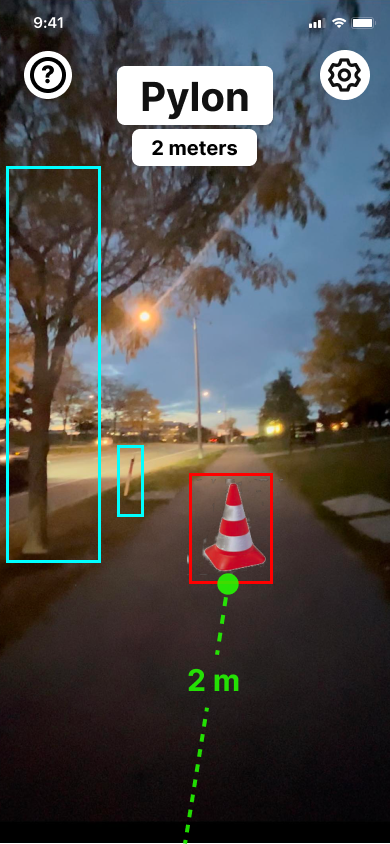
Visual medium fidelity was created on Figma, and can be seen below.
A sample of what the voice output for the app would ideally sound like is linked in the captions. The goal is for users to either use the app's voice output or Apple's voice control functionality as a way of navigating the app.
.png)
📷 Camera Covered / Bad Lighting Warning

🚨 Emergency Page 1 (Link to Audio 🔈)
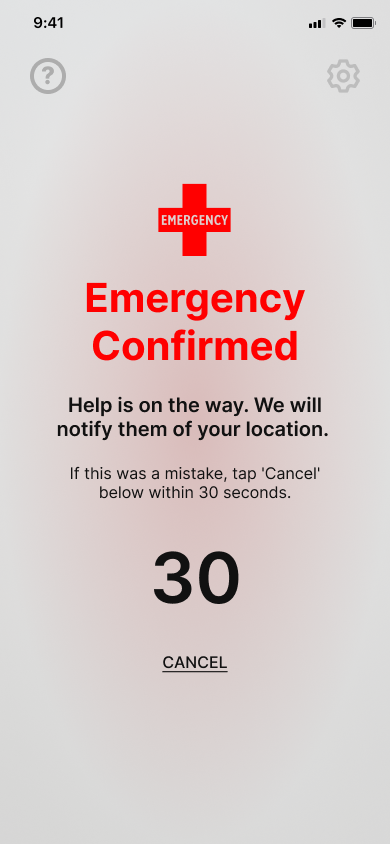
🚨 Emergency Page 2 (Link to Audio 🔈)
Feedback System
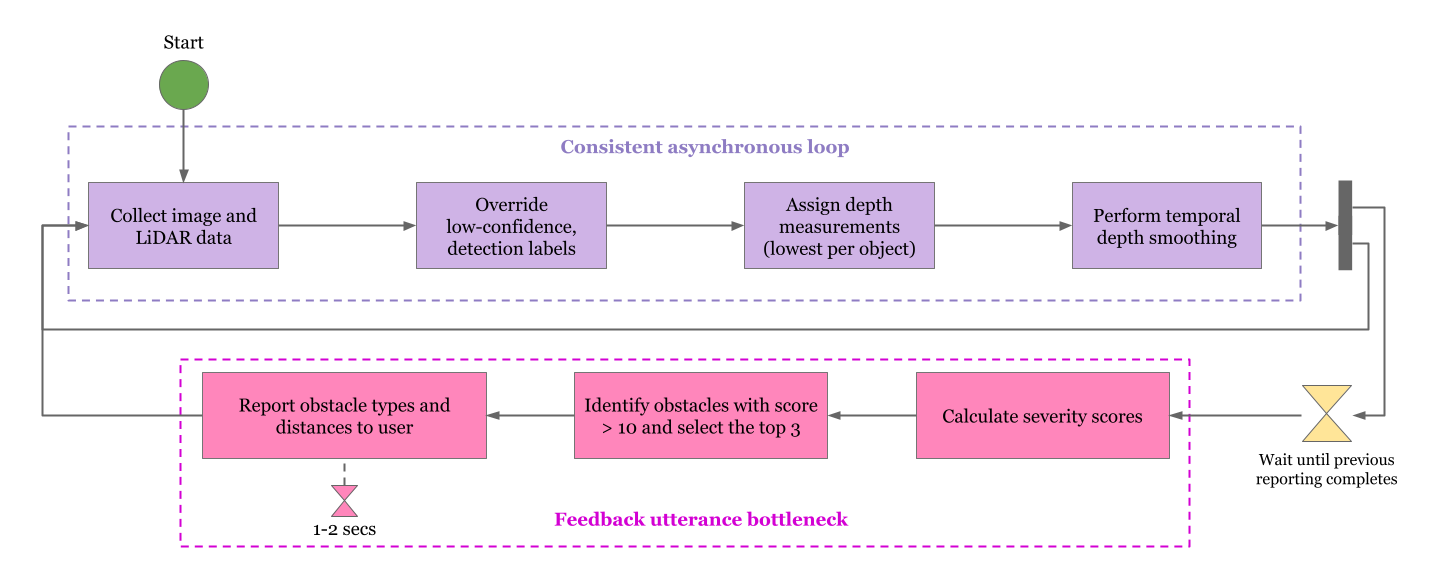
At any given point in time, we plan to track depth measurements while audio instructions are being given, so that better estimates in the rate of change of depth of all detectable obstacles can be generated.
At every point in time for which instructions are not currently being given, which we can call the ‘stagnant period’, our solution will perform depth estimation (using LiDAR) and obstacle detection, recalculating Severity Scores for all detected objects.
During the stagnant period, any object with a Severity Score exceeding some threshold value, which we can initially set to be 10, will be reported.
In the case that many obstacles simultaneously meet the threshold, the top three in terms of severity score will be reported, in an effort to provide adequate information without resulting in too long of a delay before re-triggering the obstacle detection, depth determination, and severity score calculation functions.
Severity Score Equation:
S=aH+bg(D)+cf(S)
- S is the calculated severity score
- H is a quantified ‘hazard score’ corresponding to each type of object
- g(D) is a ‘depth severity transformation’ that assigns a depth-based severity from the depth of an obstacle
- f(S) is a ‘speed severity transformation’ that assigns a severity from the rate of change of depth of an object
- a,b,c are coefficients found experimentally
Proof of Concept
A proof of concept with the data model and depth estimation implemented is shown below. It shows that the fundamental features that our project aims to possess is possible, however, with fine-tuning needed.
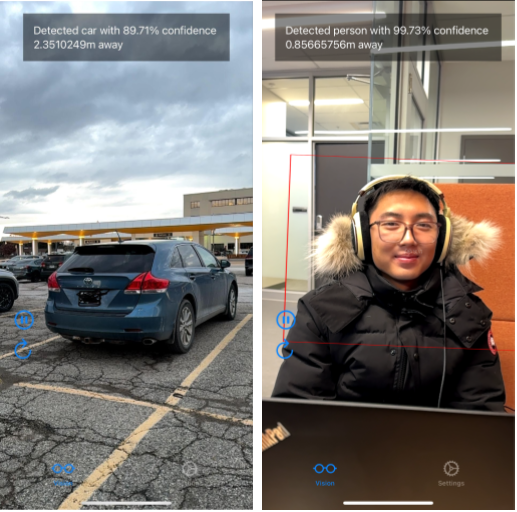
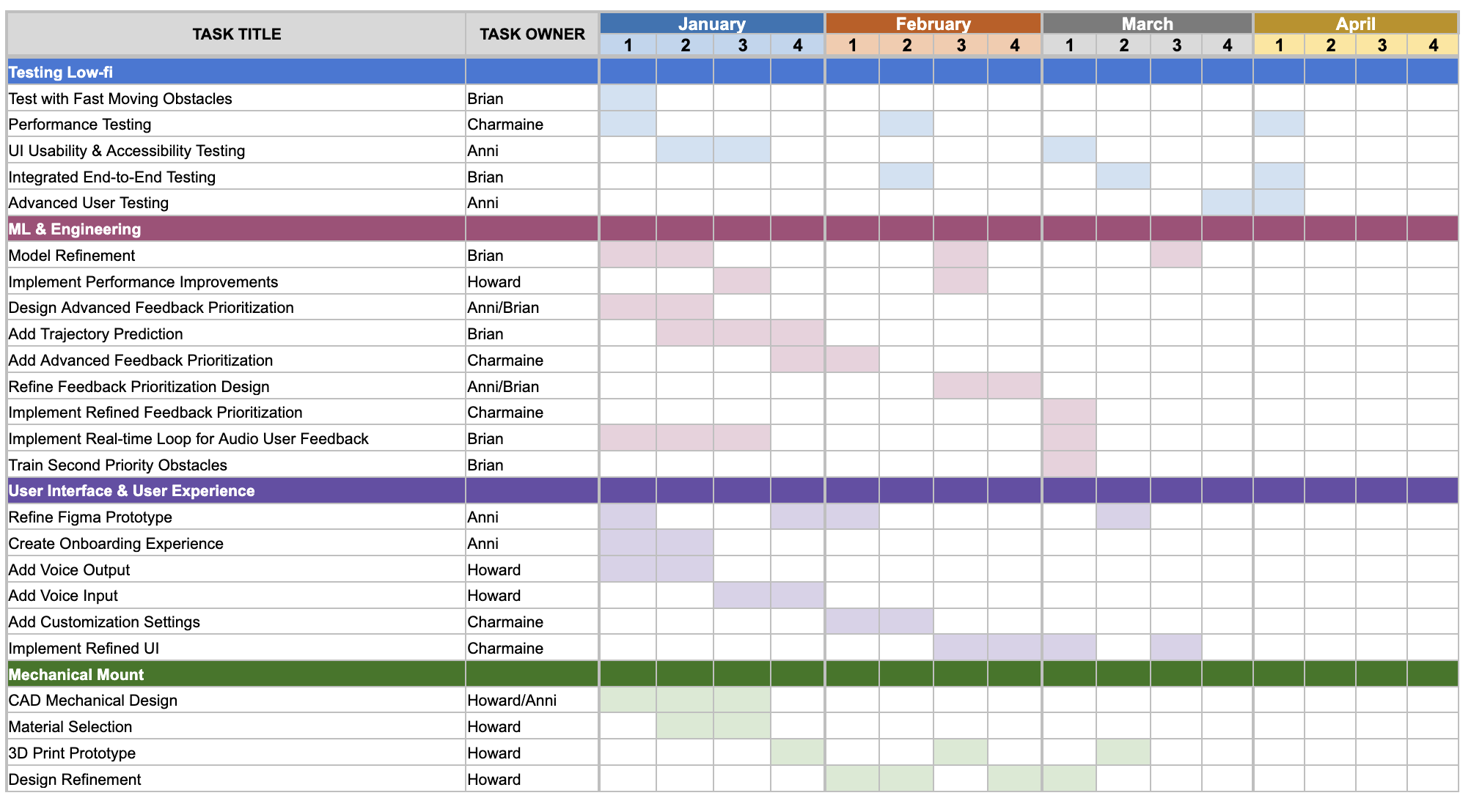
Next Steps
From January 2024 to April 2024 is the final section of our program, and second half of the capstone course. In this coming term we aim to accomplish the following: